An Introduction to Cryptography¶
In this research document, I will discuss some cryptographic principles and practices to understand encryption. I will be demonstrating some examples by making use of the Cryptography library in Python.
Firstly, I would like to discuss the most standard encryption algorithms to this date: AES, RSA, ECC, and SHA (for hashing). I will include the inner workings and provide examples with best practices.
AES¶
AES stands for Advanced Encryption Standard and is a symmetric encryption algorithm, meaning the same key is used for both encryption and decryption. It is a secure and pretty fast encryption algorithm, if implemented correctly.
How it works
AES is a block cipher, which is an algorithm that operates on fixed-length groups of bits, called blocks. The key-size of AES can be 128/192/256 bits, but it encrypts data using 128 bit-sized blocks, which is equivalent to 16 bytes. This means that it can use these 3 lengths of bits as an input, and outputs encrypted cipher text with a bit-length of 16 bytes (128 bits).
Why exactly is encrypting using a bit length of 256 better in terms of security, but slower than a 128-bit length? Let’s break that down.
The security of AES encryption depends on the size of the key space, which is determined by the bit length of the key. As I mentioned before, the key-size of AES can be 128, 192, or 256 bits long. A 128-bit key provides 2¹²⁸ possible combinations, while a 256-bit key provides 2²⁵⁶ possible combinations, which, in theory, makes it stronger to e.g. brute-force attacks.
The reason why it takes longer to encrypt/de-crypt a 256-bit length key, is because a longer key length needs more complex mathematical operations, so it takes longer to compute a larger key in comparison to a shorter one.
Testing¶
Key Generation¶
I will elaborate the theory by providing an example written in Python with the Encryption module. We will operate with hazmat, the hazardous materials of the cryptography library. In its most basic form, cryptography uses Fernet, but to use different kinds of encryption methods, one needs to dive into the hazmat section, as implementations made with these functions are more prone to being implemented wrongly. With that out of the way, let’s get started.
Firstly we create a randomly generated salt using 16 bytes as the length. The salt is used as an additional input to increase the security of key derivation to ensure that the derived key is unique, even if the same password is used multiple times.
Next, we use PBKDF2HMAC (Password-Based Key Derivation Function 2 Hash Message Authentication Code), which is a password-based Key derivation function in combination with the integrity and authenticity assurance of HMAC. PBKDF2HMAC is then used in combination with the SHA-256 hash algorithm to derive a secure AES key from a password.
AES-256 requires a 256-bit key, so a 32-byte key is suitable (16 bytes is equivalent to a 128-bit sized key). The key derivation function is responsible for producing a key of the desired size.
Finally, iterations=100000 means that the underlying hash function (SHA-256 in this case) will be applied 100000 times to derive the final key. Multiple iterations slow down key derivation, adding computational expense for attackers attempting brute-force or dictionary attacks, and thus more protected against brute-force or dictionary attacks.
In the example part, PBKDF2 is used with SHA-256 as the hash function to derive a secure AES key from a password.
But in this part, we only created a key from the password. We have yet to encrypt something using our generated key.
Message Encryption Using a generated key¶
In the first part, the generate_aes_key(password) is used to derive an AES key from the password as an input. The resulting key is then used in the encryption part that comes next.
In the function above, we’ll try to encrypt a message, in this case a plain-text string. In the first line of the function, cipher starts with specifying the the AES algorithm through the Cipher class with the key as an input. This key is in the return line of the key generation function in the first part of our experiment.
AES encryption modes
Next, it specifies in which mode of operation AES should run. In this case, it’s ‘ECB’.
As I mentioned before, AES operates on fixed-size blocks of 128 bits of data (16 bytes). ECB stands for Electronic CodeBook.
From Wikipedia:
“The simplest (and not to be used anymore) of the encryption modes is the electronic codebook (ECB) mode (named after conventional physical codebooks). The message is divided into blocks, and each block is encrypted separately.”
Warning
Although it is generally not recommended to use this mode of encryption due to its lack of variability and it not being suitable for encrypting data in general any longer, I will use it as a simplified approach to showcase how cipher blocks work.
The ECB method lacks diffusion (hiding the plaintext statistics by spreading it over a larger area of ciphertext). Because ECB encrypts identical plaintext blocks of data into identical ciphertext blocks as mentioned earlier, it does not hide patterns well, making it not recommended for use in cryptographic protocols.
Writing it down is one thing, but to truly understand, you’ll have to experience it for yourself.
So, we’ll take a detour for a moment and convert our Python encryption block above to something that shows ECB blocks step by step:
in the example above, we start with the same start of the function by providing the Cipher algorithm and the encryption mode for AES.
The use of padding
Next, we add some padding. Padding, specifically in the context of of encryption, is a process of adding extra bits to a piece of data to make it fit a specific block size. But why should we need it?
AES in ECB mode operates on fixed-size blocks of data. Let’s say we take in 128-bit size blocks for AES, but the provided plaintext cannot divide itself evenly over 128-bit sized blocks, it needs extra padding to make up for the length.
So, If the length of the plaintext is a multiple of the block size, it means that the length can be divided evenly into complete blocks without any remainder. If it’s not a multiple, there will be a remainder when dividing by the block size and padding might be needed.
Let’s say the block size is 16 bytes (128 bits). A plaintext length of either, 16, 32, 48, and so on, would be a multiple of the block size. If the plaintext is not a multiple, additional padding ensures that the last block is filled to make it a multiple. In our example above, we use the padding standard scheme PKCS#7.
Info
The word “plaintext” consists of 9 characters. Typically - assuming ASCII or UTF-8 encoding - each character typically requires 1 byte.
In this case, the word “plaintext” would be 9 bytes long.
In the context of AES with a block siz of 128 bits (16 bytes) is a length of 9 bytes not a multiple of 16. We need additional padding to make up for it.
PKCS#7 adds bytes equal to the number of bytes needed for padding. For “plaintext”, it would look like this:
"plaintext\x07\x07\x07\x07\x07\x07\x07"
\x07 represents the number of padding bytes (7 bytes) to make the total length a multiple of 16 bytes.
Padding is not always needed. In cases where padding introduces issues or it needs to be implemented and used in a more simpler way, methods like Ciphertext Stealing (CTS) can be used. CTS is “a method of using a block cipher mode of operation that allows for processing of messages that are not evenly divisible into blocks without resulting in any expansion of the ciphertext, at the cost of slightly increased complexity”, which means that it can encrypt a plaintext block without padding the message to a multiple of the block size. So, instead of adding extra padding to fill up the block, this method “steals” some ciphertext from the previous block to complete the last one.
Now that we know that padding is needed, we add it to the script as in our example above.
After that, a for-loop is introduced which iterates over blocks of the padded plaintext using the block size of AES with ECB, which in this case is 16 bytes.
block = padded_plaintext[i:i + algorithms.AES.block_size] extracts a block of data from the padded plaintext. It starts with i and includes the next AES block size bytes.
Next, the current block is encrypted using AES. This, of course, happens block per block. After encryption of the current block, it appends the encrypted block to a list called ciphertext_blocks.
After that, it tries to print the hexadecimal representation of the current plaintext block, and the ciphertext (encrypted) block below it.
It repeats this process until no further blocks are found.
After the loop ends, return b''.join(ciphertext_blocks) is used to concatenate (or simply join them together) into the final encrypted data, which is printed as well.
At the end, we add the sixteen byte key and a plaintext worthy of having 2 blocks. The output looks somewhat like this:
Interestingly, Block 2 has a lot of 0bs in its plaintext. 0b is hexadecimal, and represents the number 11. this means that 11 bytes of padding were added. The padding in this plaintext is identified as the last 11 bytes, represented as 0b0b0b0b0b0b0b0b0b0b0b.
In the encrypted data below it, nothing is left of the appended padding on the plaintext.
The final encrypted data is shown in a hexadecimal format, and will always be the same. ECB mode does not provide semantic security, and the same plaintext blocks will always produce the same ciphertext blocks, hence the lack of variability explained earlier.
Modes of Operation¶
Now is a good time to talk about operation modes. As discussed prior in the AES segment, ECB is one such mode, but not secure in the slightest. Taken from the same Wikipedia page: “The purpose of cipher modes is to mask patterns which exist in encrypted data.”
If ECB is not capable of masking in a secure way, than what modes are?
CBC (cipher block chaining) is one of the most widely used mode of operation. However, it still has its drawbacks. 2 of them are as follows: the use of sequential encryption and that messages must be padded to a multiple of the block size, just like ECB.
Like ECB, CBC makes use of sequential encryption, which refers to encrypting data in a linear manner; typically, one block of data at a time. As seen in the examples above, data is typically divided into fixed-sized blocks, and the encryption of one block is dependent on the encryption of the previous block. However, even if ECB and CBC both use sequential encryption, they are fundamentally different. In ECB mode, each block is encrypted with the exact same key, whereas with CBC, each block is XORed with the ciphertext of the previous block before encryption. This is called a chaining mechanism and should provide better diffusion than not using chaining at all.
Obviously, the opposite variant is parallel encryption, which encrypts multiple blocks of data simultaneously.
The most obvious bonus point is its speed of encryption. However, it might be more suitable for multi-thread architectures as it needs to exploit parallel processing power.
Parallel encryption is not necessarily more secure than sequential encryption, if implemented correctly. Both have its advantages and concerns. Parallel encryption for example, may have faster processing times, but might introduce new vulnerabilities because it is less tested than sequential encryption in e.g. CBC mode.
There exist many different modes and variants, with each their own advantages, use-cases, and drawbacks.
RSA¶
RSA stands for “Rivest-Shamir-Adleman”, which are the 3 last names of the founders of this method of encryption. RSA is a cryptographic system that involves a public and a private key. The public key is used for encryption, and the private key is used for decryption.
How it works
RSA makes use of a private key and a public key. When presenting 2 parties - call them Alice and Bob - each of them has their own private and public keys. The private key is obviously private to its own party, but the public key can be shared to anyone. Unless implemented badly, messages encrypted using the public key can only be decrypted with the private key.
RSA encryption is not typically used to directly encrypt large messages. Encrypting something using a public/private key pair is usually done to confirm the authenticity of the content. You cannot encrypt a lot of information with the RSA encryption technique, but you can encrypt a large message content separately using AES.
So, encrypting something using a public/private key pair like RSA, is commonly employed for ensuring the authenticity and confidentiality of the content. However, due to the computational cost associated with asymmetric encryption algorithms like RSA, they are not as efficient for encrypting large amounts of data directly.
Testing¶
Key Generation¶
The private key is the main part of RSA and is generated using a public exponent, a key size and a backend.
A public exponent is a typically small, odd prime number in the form of an integer. This public exponent is used in the public key, which is employed for the encryption process.
The commonly used public exponent in RSA, 65537, is a Fermat prime number. Fermat primes are a special class of prime numbers that have the form 2 to the power of 2 to the power of n + 1. In the case of 65537, it is the result of 2[^16]+1.
A is a prime number with 2 bits. Some common Fermat primes are 3, 5, 17, 257, and 65537. The number 65537 is used simply because it is believed that there does not exist a higher Fermat prime number. Fermat is used because it simplifies the exponentiation operation, which is how we calculate the numbers using Fermat.
65537 is also often chosen because it has a low Hamming weight. The Hamming weight a binary string is the count of the number of non-zero bits, or literally “1” bits. The Hamming weight of the binary string “1101” is 3. With this logic, our integer 65537, which is 0000 0000 0000 0000 0001 0000 0000 0000 0001 in binary, has a Hamming weight of 2, which is reasonably low; it makes modular exponentiation more efficient.
Aside from the public exponent, we need to specify a key size. As explained in the AES part, longer key sizes provide higher security, but they also increase the computational cost of cryptographic operations. In many cases, a key size of 2048 is considered a standard and quite common, because of its balance between security and computation efficiency. While a 2048 key size is valid until 2030, there are more and more cases where 4096 as a key size is use.
The second part is where serialization happens. Serialization is the process of converting the private key into a format that can be easily stored and transmitted. The private key is stored in the .pem format (Privacy Enhanced Mail). It is a text-based encoding format used for encoding cryptographic objects like RSA keys.
PKCS#8 is private key syntax format. PKCS#8 private keys can be encrypted using a passphrase, however, In our example, no encryption is applied to keep it in the code and not manually resort to files. Some examples on when this could be done is e.g. in SSH keys.
The same is done in the public key part. The only difference being is what information is being shown. A public key certificate needs less information, so specific data is omitted.
Printing these out will result in the following private key:
And a public key that we can distribute.
All in all, RSA is a solid cryptographic mechanism that is widely used in different kinds of environments, and thus standardized. Furthermore, it’s dependency on difficult mathematical security is very beneficial, making it more resistant to all kinds of attacks.
What is ECC?¶
Elliptic Curve Cryptography (ECC) is another type of cryptographic method that uses the mathematics of elliptic curves to secure communication. It involves generating public and private key pairs just like RSA, but based on points on these curves, making it computationally efficient compared to other traditional methods. This is because while it provides similar security to RSA, it has smaller key sizes.
ECC can be used for key exchange and digital signatures in protocols like ECDH and ECDSA.
Despite using shorter key lengths, ECC provides robust security, and its resistance to quantum attacks makes it a valuable choice for secure communication and authentication in various applications. But how does this work?
How does it work?¶
First, let’s talk about elliptic curves.
Elliptic curves in cryptography specifically is an approach to public-key cryptography based on the algebraic structure of elliptic curves over finite fields, as quoted by Wikipedia. I don’t want to get too much into Elliptic curves and finite fields as they go more in-depth in mathematics, which isn’t my strongest point.
Elliptic curves in cryptography are in many cases used by combining an agreement on a key and a symmetric encryption scheme. The use of elliptic curves is a bit of a controversy, considering that it was included as a NIST standard due to the influence of NSA. In 2013, which was around 7 years after wide spread of the use of elliptic curves in cryptography, RSA security recommended its customers discontinue using software based on a specific method in elliptic curves called “Dual_EC_DRBG due to an exposure of this as “an NSA undercover operation”, including many other cryptography experts agreeing on non-elliptic curve groups being preferential over elliptic curve based encryption.
I don’t want to get into the mathematics too much; that goes beyond me, but we can do it another way.
Elliptic curves can be show-cased using actual curves. I think it is pointless to write it all down here, so let’s appreciate the effort of making this video by watching this short segment on it:
https://youtu.be/gAtBM06xwaw&t=366
It is quite difficult to find code examples or other useful elliptic curve cryptography use cases. Even when I try using AI to get some results, it fails to do so. The difficulty of finding examples of the “finite” ECC implementations is due to multiple reasons:
- Elliptic curves are extremely complicated, and very few people understand it and can do the math
- Many of them are patented, unlike using it with the well known Diffie–Hellman protocol
- Furthermore, it is heavily depended on a good randomness. ECC fails on insufficient randomness
ECDH is actually a pretty important piece of information. ECDH stands for Elliptic Curve Diffie Helman, which takes a “Diffie Helman approach” to and with elliptic curves.
What is the Diffie–Hellman key exchange protocol?¶
Diffie–Hellman key exchange is one of the most well known key exchange protocols at this point in time. Reading the name however, this protocol does not appear to exchange actual keys. In actuality, some public variables are exchanged, which are then combined with some private variables that are kept hidden, enabling both parties of the variables to create the same key.
Let’s go over it in a simple example:
If we take Alice and Bob as parties that want to create a way for communication, they have to share and agree on some public variables first. 2 variables are out in the open: G and n, where G is the generator and n is the
Aside from that, both Alice and bob both generate a private key locally, let’s call them a and b respectively. Private keys are never shared with anyone.
Starting with Alice: Alice takes her private key and combines it with G. Bob does the exact same, but for his own private key. We now have two different variables, aG and bG. Then aG and bG are exchanged with Alice and Bob.
Using letters only, it might look simple, but when you switch them for actual numbers (preferably big ones), it get’s really difficult to find out some numbers.
As an outsider, you know what G is, as it is public. But knowing what aG is, you’d have to know what a initially was, which is quite difficult to figure out.
In the last bit, Alice takes Bob’s public message, and adds her private key, which is a. Bob will do the same, but the other way around, of course. Alice and Bob both made abG, as they add their own private a and b to the sent public key. Now, Alice and Bob both have the same key.
What are Elliptic Curves?¶
Now, how does this apply to the combination with elliptic curves?
ECDH and ECC are closely intertwined concepts, as ECC provides the mathematical foundation for ECDH. This means that ECDH uses the above explanation about Diffie-Helman, but uses mathematical operations from the elliptic curve cryptography process.
As mentioned before, ECC utilizes the algebraic structure of elliptic curves over finite fields to perform cryptographic operations. These curves offer several advantages over traditional public-key cryptography based on prime numbers.
These curves can be mapped out like so:
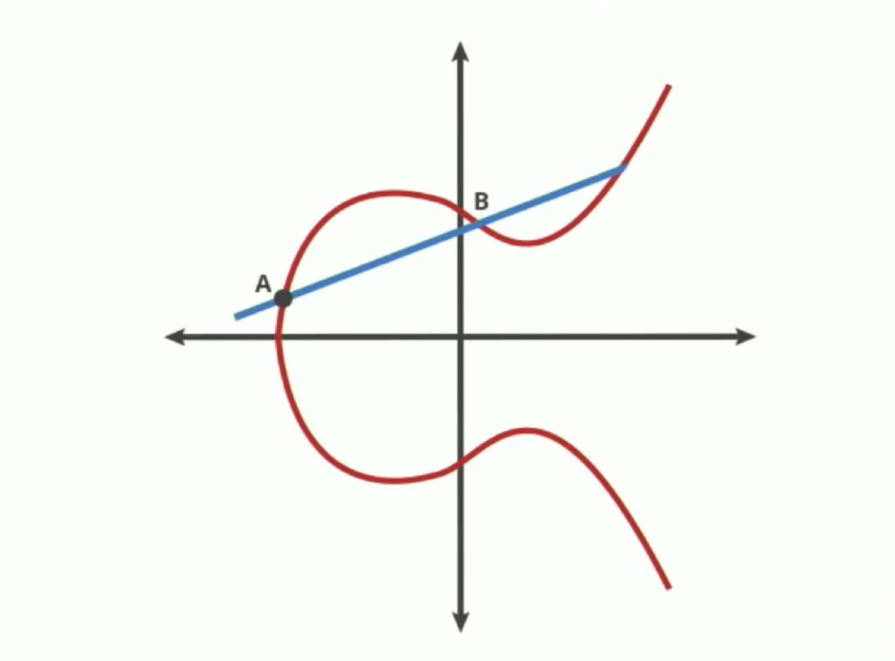
So in this example, a curve is drawn over a finite field. A and B are two points on the elliptic curve. When we draw a straight line from point A to point B, the line will intersect the curve in at most one place. When it reaches to end of the curve, the line will flip itself over the X-axis and make a line to the next point.
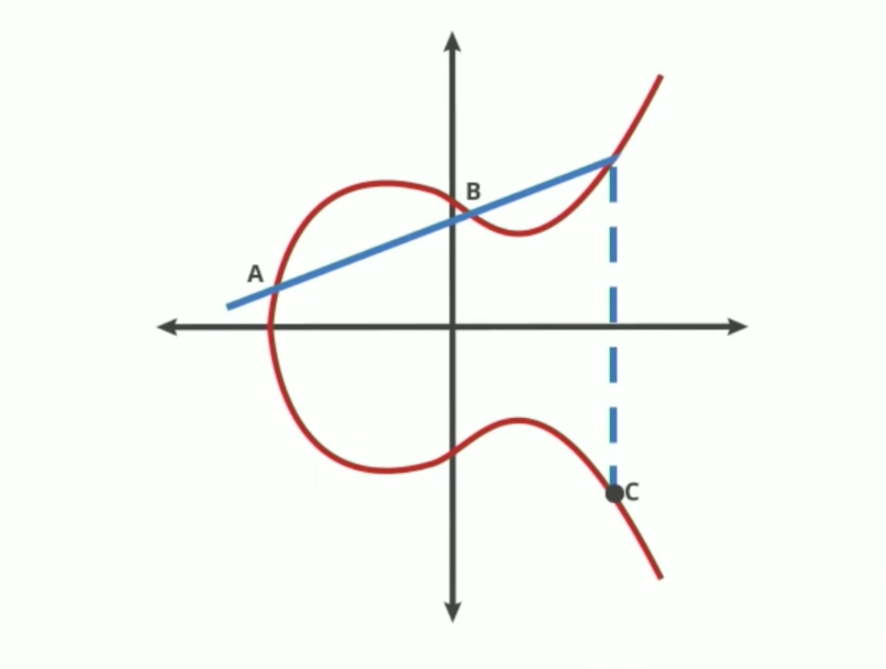
Now that we know where C is, we make a new line with A and C:
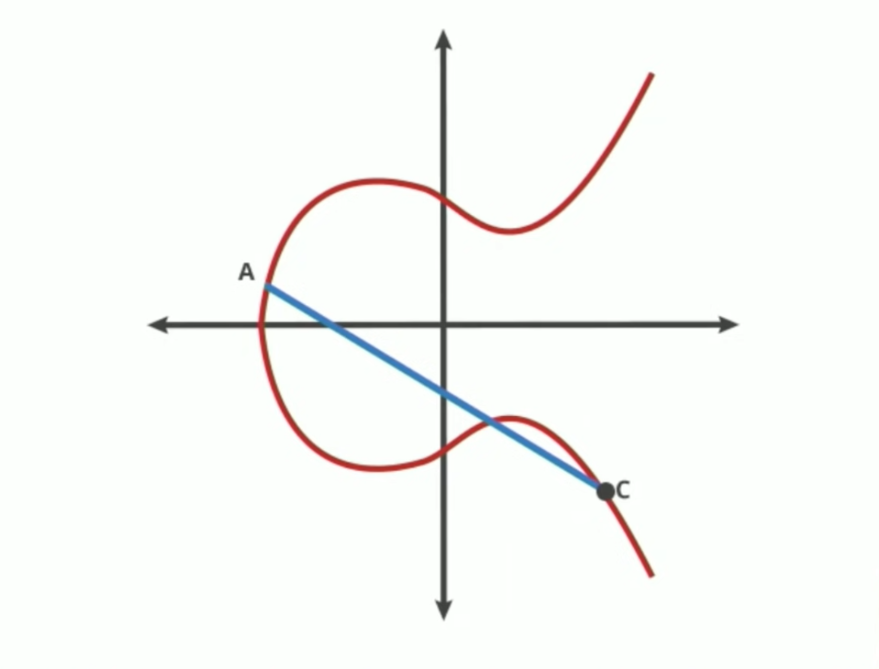
We flip it over the X-axis again to create a new point called D. This process starts over and over again, until we get really deep into the curve.
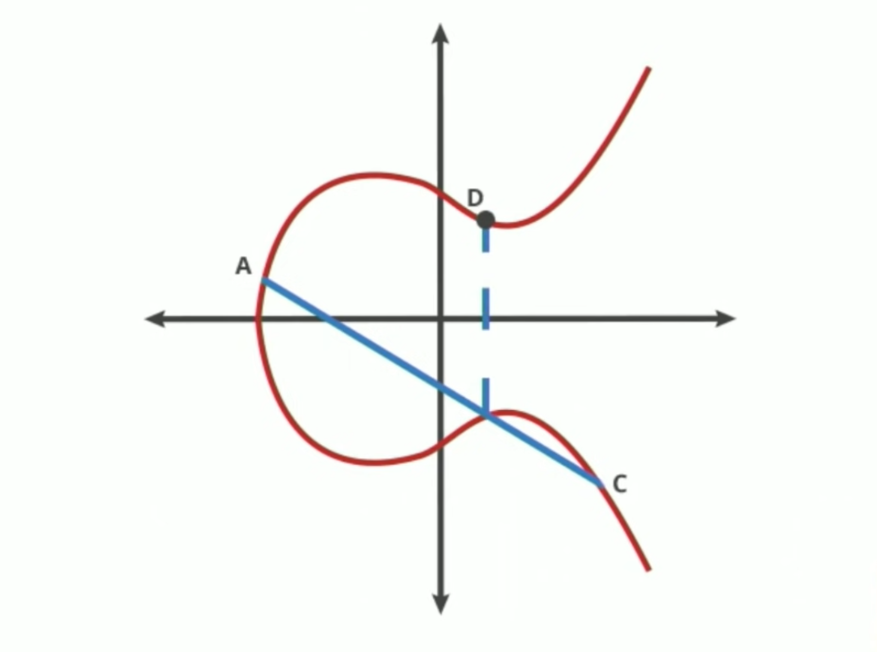
At a certain point, you come to understand that it becomes really difficult to figure out where you started out, even we do not use actual numbers in this example.

This approach can be quite similar to exponents in a way, where even if you know what the values of point A and point E are from the pictures above, it is really difficult to figure out how it got there, or in other words: how many times it did the elliptic curve operation.
I would highly suggest you to view the full video that is linked above in order to understand the mathematical operations.
My understanding on ECC¶
The process of understanding the concept is fun, but getting into the complexity of mathematical operations at this point in time is not working in my favour to understand ECC as a whole right now.
If I could rephrase it with Alice and Bob, I would say that Alice and Bob would agree on a base point on a common variant of an elliptic curve, like the one we see above.
What is SHA?¶
We’ve come across SHA multiple times in now, so now is the time for a deep-dive.
SHA stands for Secure Hash Algorithms. Hash functions are algorithms that take an input or message and produce a fixed-size string of characters, which is typically a hexadecimal number, but it depends on the application.
Testing¶
I use hashlib instead of cryptography because it is just easier. Sorry about that.
The SHA-256 hash object is created using hashlib.sha256(). Then, we update the hash object with the input data using the update() method. The update() function can merge multiple update functions together, because it sees repeated calls as one single call.
Finally, we obtain the hexadecimal form of the hash using the hexdigest() method and put it in a variable, which we then print.
The SHA-256 hash of our message is:
It will remain the same, no matter how many times you run the script, unless you change the data.
How does SHA work under the hood?¶
The example makes use of the hashlib library, which takes care of the details of SHA-256, but we’ll zoom out a bit for now.
Versions of SHA¶
In a nutshell, a hash function takes a string and turns it, usually, in a fixed length bit-string of randomness. However, this is SHA works in similar cases. There are a couple of SHA versions out there:
SHA-1
SHA-1, which first appeared in 1995 following a revision from SHA-0 that existed since 1993, has a 160 bit hash value in length. It has been slowly declared as insecure since 2005, and had a formal goodbye wave by NIST in 2011. Despite it’s deprecation, even by bigger tech companies, it’s still widely used. However, support has been dropped steadily over the years.
SHA-2
SHA-2, designed by the NSA and published in 2001, has seen a lot of changes when compared to its parent SHA-1. SHA-2 houses 6 hash functions with hash values of 224, 256, 384 or 512 bits in length: SHA-224, SHA-256, SHA-384, SHA-512, SHA-512/224, SHA-512/256. SHA-256 and SHA-512 are very popular. It’s pretty robust, but not entirely immune to several attacks like length extension attacks and preimage attacks, although only partial. This is often done through Finding likenesses between certain values or straight-up guessing numbers. It is currently used in products like TLS, SSL, PGP, and SSH, among others.
SHA-3
SHA-3 was released by NIST in 2015. Although part of the same series, its internal structure is fundamentally different from SHA-1 and SHA-2. Where these 2 were more like MD5-type structures, SHA-3 uses and has some proposals for additions that make it more robust, flexible, and more secure in general. It is supposed to be a direct replacement, but we’ll put that to rest for now, as it is not as known and widespread as SHA-2. It is, however, already supported by numerous cryptography libraries.
All variants of the SHA algorithms are one-way hash functions. One-way hash functions are mathematically easy to compute one way, but not the other way back. I’ll tell you something more; without knowing the algorithm used, there is no way to to reverse the hash.
Now, time to shift back to our example and SHA-256. SHA-256 works with bit arrays and starts starts with a set of eight 32-bit initial hash values, which are randomly chosen.
The input message, in our example data, is padded to a multiple of the block size, which would be 512 bits for SHA-256; each block is 512 bits long.
For each block, 64 rounds of processing are performed. Each round involves a series of complex calculations that combine the current hash values with the contents of the then current block. After each round, intermediate hash values are updated based on the results of the calculations, just like with the update() function we saw in our example. Finally, when all blocks have been processed, the final hash will be calculated using all intermediate hash values using a mathematical formula. This final hash is a unique 256-bit string, representing the original input data.
Conclusion¶
Cryptography is essential for keeping data safe on the internet. AES, RSA, ECC, and SHA are powerful algorithms that protect data from unauthorized access and manipulation, but can have their flaws if implemented incorrectly. AES encrypts and decrypts data efficiently, RSA verifies identities and secures communications, ECC offers smaller key sizes for faster processing, and SHA generates unique fingerprints for data integrity. I hope this document was helpful in any way.
Afterword¶
Honestly speaking, this topic is incredibly difficult to understand, and I am sure I missed a lot of key parts on how certain mechanics work. However, diving too deep into this rabbit hole is not the main purpose of this assignment, and will only worsen my understanding of this topic at this point in time. With that being said, I think this is a very interesting subject, but it requires a significant amount of time in order to research this, as there is a lot to discuss. I hope I provided some entry-level explanations on cryptography in this document.
Sources¶
- NIST’s Cryptographic Hash functions, encryption algorithms, and keys - https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-57pt1r5.pdf (page 40)
- The concept of AES and its use of operation modes - https://crypto.stackexchange.com/questions/57645/is-using-the-same-iv-in-aes-similar-to-not-using-an-iv-in-the-first-place/57648#57648
- Information about ECB - https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation#Electronic_codebook_(ECB)
- Information about CBC - https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation#Cipher_block_chaining_(CBC)
- AES/ECB mode with padding and its security- https://stackoverflow.com/questions/10531932/aes-ecb-mode-requires-padding-how-come-we-have-this-aes-ecb-nopadding-then
- Using padding in encryption modes and its usage recommendations - https://crypto.stackexchange.com/questions/71365/why-does-a-padding-block-exist-for-ecb-and-cbc-modes
- Information about CTS - https://en.wikipedia.org/wiki/Ciphertext_stealing
- Information about RSA - https://en.wikipedia.org/wiki/RSA_(cryptosystem)
- More information about RSA - https://www.youtube.com/watch?v=ZPXVSJnDA_A
- Key size selection RSA - https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-57pt1r5.pdf (page 65)
- Information about Hamming weight: https://en.wikipedia.org/wiki/Hamming_weight
- Public exponentiation: https://crypto.stackexchange.com/questions/22437/rsa-public-key-exponent-generation-confusion and https://stackoverflow.com/questions/6098381/what-are-common-rsa-sign-exponent
- Information about known Fermat primes: https://crypto.stackexchange.com/questions/3110/impacts-of-not-using-rsa-exponent-of-65537
- RSA key size standards: https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-78-5.ipd.pdf
- PKCS#8: https://en.wikipedia.org/wiki/PKCS_8
- Information about ECC: https://en.wikipedia.org/wiki/Elliptic-curve_cryptography
- Information about Elliptic curves: https://en.wikipedia.org/wiki/Elliptic-curve_cryptography
- RSA Security as a company: https://en.wikipedia.org/wiki/RSA_Security
- More on ECC: https://blog.cloudflare.com/a-relatively-easy-to-understand-primer-on-elliptic-curve-cryptography
- SHA: https://en.wikipedia.org/wiki/Secure_Hash_Algorithms
- python cryptography: https://cryptography.io/en/latest/hazmat/primitives/asymmetric/utils/
- Information on the SHA algorithm: https://en.wikipedia.org/wiki/Secure_Hash_Algorithms
- Hashlib: https://cryptography.io/en/latest/hazmat/primitives/asymmetric/utils/#cryptography.hazmat.primitives.asymmetric.utils.Prehashed and https://docs.python.org/3/library/hashlib.html#hashlib.sha256
- SHA-1: https://en.wikipedia.org/wiki/SHA-1
- SHA-2: https://en.wikipedia.org/wiki/SHA-2
- SHA-3: https://en.wikipedia.org/wiki/SHA-3
- Information on MD5 hashing: https://en.wikipedia.org/wiki/MD5
- IETF (section 4): https://www.ietf.org/rfc/rfc6234.txt
- NIST SHS on SHA-256 functions (page 15): https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.180-4.pdf